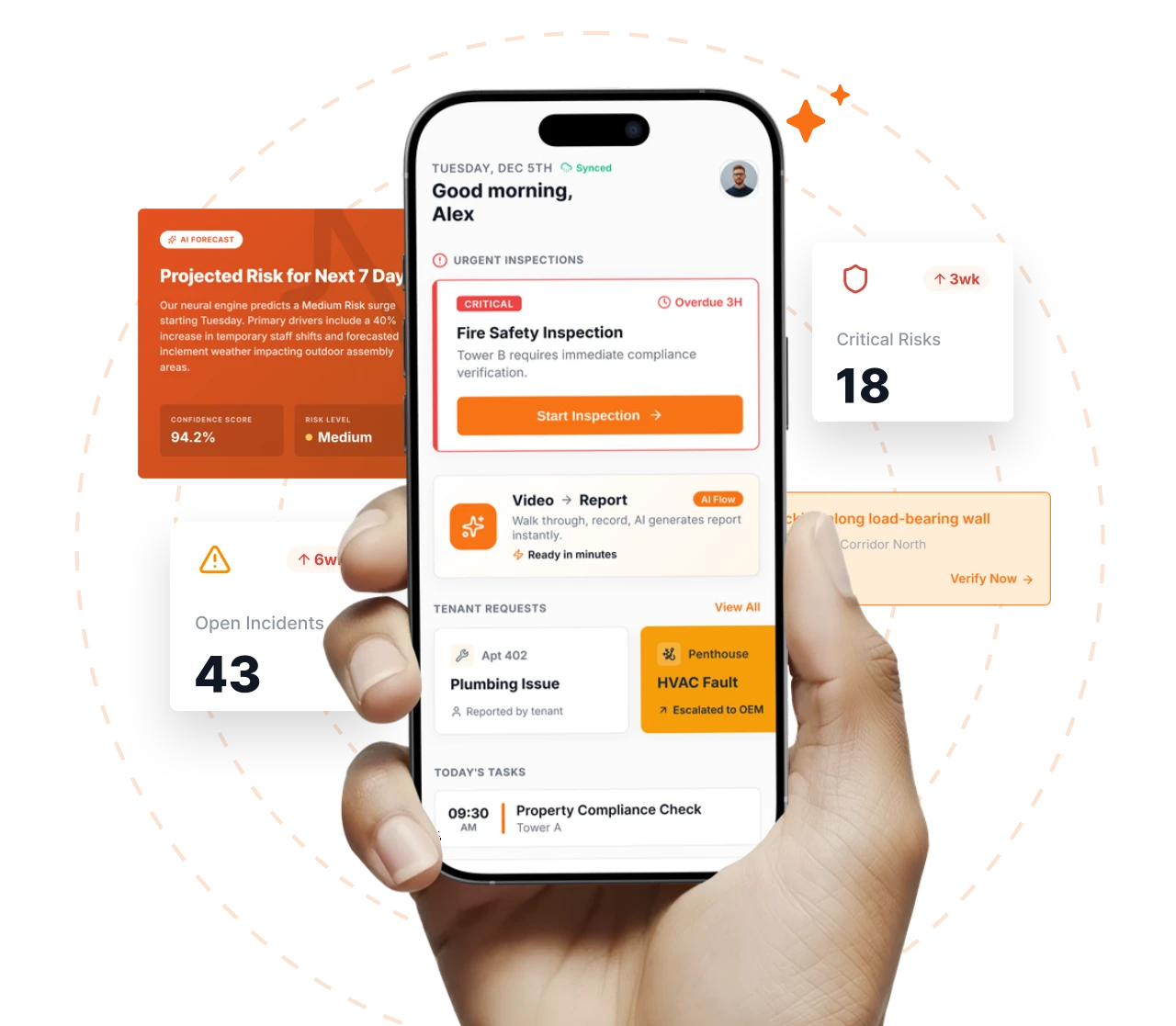
Take a Photo. AI Fills the Form
Your inspector takes a photo of any asset or defect. AI reads it and fills the inspection form automatically. No typing. No manual entry.

Convert your checklist into Mobile App
One issue platform for operations managers and site managers running multi-site programs where 'marked done' and 'actually fixed' have to be the same thing. Every issue carries assignment, deadline, escalation path, photo evidence, and verified closure aligned to the SLA the operation is measured on.
Issue tracking and resolution software is a mobile-first system that captures, assigns, escalates, and verifies the closure of every operational issue raised by an inspection, complaint, audit finding, or field observation. It replaces WhatsApp issue threads, email punch lists, and spreadsheet trackers with one defensible workflow that owns the issue from capture through 5 Whys or Ishikawa root cause to verified closure.
Everything your field team does on paper, Inspectly360 does automatically: faster, more accurate, and without the admin.
Your inspector takes a photo of any asset or defect. AI reads it and fills the inspection form automatically. No typing. No manual entry.

Inspectors speak their observations in any language. AI transcribes and fills the form in real time. Completely hands-free in the field.

The moment an inspection is submitted, a branded PDF, Excel, or CSV report generates automatically. No manual work. No waiting.

Inspectly360 integrates with the tools your team already uses, including Zoho, Microsoft 365, and SAP. No double entry.

Your operations team sees completion rates, open issues, and compliance scores across all sites in real time. No chasing updates.
What changes once issue tracking & resolution runs on one mobile-first platform with photo proof and live dashboards.
Issue tracking and resolution software is a mobile-first system that captures, assigns, escalates, and verifies the closure of every operational issue raised by an inspection, complaint, audit finding, or field observation. It replaces WhatsApp issue threads, email punch lists, and spreadsheet trackers with one defensible workflow that owns the issue from capture through 5 Whys or Ishikawa root cause to verified closure. Inspectly360 is built for Operations Managers and Site Managers running multi-site programs where contractor self-certification, repeat issues, and SLA breaches each carry a direct revenue or compliance cost.
For the field team, a failed inspection item, a customer complaint, or a contractor observation creates an issue with photo evidence, location, severity, and the originating context attached. Voice AI captures the description without typing; AI smart suggestions pre-fill category and likely owner; the inspector confirms or overrides. The issue is on the right person's screen before the inspector leaves the site.
For operations leadership, every issue carries SLA-aware escalation, verified-closure evidence, and root-cause coding. Repeat-issue detection surfaces the same fault recurring on the same asset, zone, vendor, or category, so reliability and process teams stop treating symptoms. A live dashboard shows open, in-progress, blocked, and verified-closed work across every site, with drill-down to the originating inspection and the responsible owner. ITSM integration (ServiceNow, Jira Service Management, Zendesk) keeps issue and ticket data in sync where corporate workflow already lives.
Issue programs roll out from the inspection layer outward: capture and assignment discipline first, then SLA-aware escalation, then root-cause coding and ITSM connectivity once the operating model has earned them.
Issues are auto-created the moment an inspection item fails or a complaint is logged. Photo evidence, location, severity, and inspector notes attach automatically. Manual issue creation is allowed for off-inspection observations but inherits the same data model.
Configure routing rules that pick the right owner from the start: by category (electrical, HVAC, cleaning), by site, by vendor scope, or by skill match. Round-robin and workload balance prevent the same supervisor inheriting every issue.
Severity-driven SLA timers (critical 4 hours, high 24 hours, medium 72 hours, low 7 days) escalate to the named supervisor, the on-call manager, and the director on the documented breach windows. Quiet hours and shift-handover rules avoid waking the wrong person.
Closure requires a root-cause code (5 Whys, Ishikawa, or ITIL problem category) so issue data feeds preventive controls rather than just resolution metrics. Repeat-issue detection cross-references asset, zone, vendor, and category to surface failure modes the operation should already have controlled.
Bidirectional integration with ServiceNow, Jira Service Management, Zendesk, Zoho Desk, and Microsoft Dynamics keeps issue and ticket data in sync. Customer-facing visibility (scoped, read-only) replaces the email update with a shareable status link.
Answers to common long-tail questions, kept on one canonical page to avoid thin duplicate URLs.
Start with the issue category that hurts most today (typically reactive complaints or audit findings) at one or two sites. Convert the WhatsApp or email channel into the platform, run it in parallel with the existing channel for two cycles, and measure mean time to close, escalation accuracy, and verified-closure rate. Layer SLA timers and escalation rules once the basic capture-assign-close loop is trusted, switch on root-cause coding next, and connect ServiceNow, Jira Service Management, or Zendesk only after the field-side data the integration will carry has stabilised.
Validate SSO via SAML or OIDC, RBAC scoped to site, category, and vendor, mobile capture verified by a real inspector on a real shift, configurable retention windows aligned to customer and regulatory record-retention requirements, and the bidirectional integration path into ServiceNow, Jira Service Management, Zendesk, Zoho Desk, or the corporate ITSM and CRM already in place. Vendor and contractor scoping must be enforced server-side rather than in the UI, which matters when a third-party is part of the workflow.
Active issues import from Excel, Google Sheets, or ITSM exports with owner, current status, deadline, and attachment history preserved. Historical resolved issues import as searchable evidence so the repeat-issue detection model has data to operate on from day one. WhatsApp and email channels can stay live for the first two cycles in shadow mode by design, so adoption rests on team confidence rather than mandate.
The platform capabilities that power issue tracking & resolution across every site.
Operations Managers comparing Inspectly360 to ServiceNow modules, Jira projects, Zendesk queues, and WhatsApp issue threads care about five different things: whether the SLA can be enforced rather than asserted, whether repeat issues are detected automatically, whether root cause is structured rather than narrative, whether vendor and contractor scoping holds without exposing the whole portfolio, and whether the field-facing experience is fast enough that the inspector actually uses it instead of falling back to chat.
| Topic | Typical Gaps | With Inspectly360 |
|---|---|---|
| SLA enforcement and breach prediction | SLAs are written into contracts but enforced by manual reminders. Breach is detected when the customer complains; the operations manager learns about a missed SLA at the same time the customer raises it on Friday afternoon. | Severity-driven SLA timers run continuously; breach prediction flags issues likely to breach 25 percent before the deadline so the escalation happens before the customer notices. SLA performance per site, category, and vendor renders on the live dashboard as a number, not a story. |
| Repeat-issue detection | The same HVAC fault is flagged seven times in six weeks across three sites and nobody connects the dots. Each issue closes individually; the root cause stays invisible because the data sits in a chat thread no one reads end-to-end. | Repeat-issue detection cross-references asset, zone, category, vendor, and root cause. The dashboard surfaces the recurring fault automatically with frequency, affected sites, and trend direction. Failure modes that should already be controlled stop hiding. |
| Root-cause coding and preventive feedback | Root cause is written into the closure comment as free text and never read again. Preventive action lives in the safety manager's intuition rather than a data layer the operation can mine. | Closure requires a structured root-cause code (5 Whys, Ishikawa, or ITIL problem category) plus optional corrective and preventive actions. The data feeds continuous improvement, audit reporting, and recurring-fault analytics from the same record. |
| Vendor and contractor scoping | Contractors are given email access to the whole issue list or forwarded individual messages by the supervisor. Tenant and client data co-mingles with vendor work; the audit trail is incomplete because half the conversation lives in someone's inbox. | Vendors get a scoped mobile profile that surfaces only the issues, sites, and assets explicitly assigned to them. Photo-verified closure uploads with audit-grade event logs. Vendor scorecards reflect the same data the vendor sees in their portal. |
| Fit with ITSM, CRM, and the operational stack | Field issues sit in one tool, customer tickets in Zendesk or Salesforce, work orders in CMMS, and incidents in ServiceNow. Updates retype between systems and the same issue exists in three different states depending on which screen the manager is looking at. | Bidirectional integration with ServiceNow, Jira Service Management, Zendesk, Zoho Desk, Salesforce Service Cloud, and Microsoft Dynamics. Issue state, comments, and attachments synchronise. Customer-facing read-only links replace the email update with a shareable status URL. |
What changes once issue tracking & resolution is standardised on Inspectly360.
Get started with inspection and audit checklist templates.

Catch defects before handover and generate punch list reports in minutes. Room-by-room finish checks, evidence, and corrective actions.

Pre-handover snagging for new build apartments. Room-by-room finish checks, MEP, and defect tracking before keys.

Utilize this Scaffolding Safety Inspection Checklist to spot hazards, verify stability, and ensure compliance with safety standards before work begins.

Capture job details, measurements, work performed, photos, and sign-offs in one structured field service report form.
Use these apps to run inspections and audits.

by Inspectly360
Track operational issues from identification to resolution with ownership and closure evidence.

by Inspectly360
Digitize snagging and punch list workflows with forms, evidence capture, and automated reporting.

by Inspectly360
Assign, track, and verify corrective actions with accountability and proof of closure.

by Inspectly360
Track defects from detection to verified closure with ownership, SLA timelines, and proof.

by Inspectly360
Track incidents from report to closure with ownership, SLA visibility, and escalation controls.
Each issue inherits a severity (critical, high, medium, low) from the inspection finding, the customer complaint, or manual classification. Severity drives the SLA timer (commonly 4 hours, 24 hours, 72 hours, 7 days, but fully configurable per program). The timer respects quiet hours, shift handover, and on-call rotations so an after-hours critical wakes the on-call engineer, not the office-hours supervisor. Breach prediction flags issues likely to miss SLA at 25 percent before the deadline with a recommended action (re-assign, escalate, request extension). Escalation history is logged for accountability, and SLA performance per site, category, and vendor renders on the live dashboard so the operations review opens on the actual SLA picture rather than a sample.
AI cross-references closed and open issues by asset class, zone, location, vendor, category, and structured root-cause code over a rolling window (default 90 days, configurable). The model surfaces clusters that share two or more of those dimensions, so an HVAC fault flagged seven times in six weeks across three sites under the same AMC vendor surfaces automatically with frequency, affected sites, trend direction, and the cumulative cost. The dashboard links straight to the originating inspections, supporting evidence, and the responsible vendor scorecard, so the root-cause project starts in the same session the cluster was identified. Repeat issues stop hiding behind the volume of unrelated work.
Closure requires a structured root-cause code chosen from a configurable methodology library: 5 Whys (workflow walks the engineer through the question chain), Ishikawa fishbone (six-M categorisation with the contributing cause documented), and ITIL problem management codes for IT-adjacent operations. Methodologies can vary per program, so a manufacturing line uses 5 Whys while a service-desk integration uses ITIL codes. The closure form prevents save without a root-cause code, which is the discipline auditors look for when continuous-improvement programs claim maturity. The structured data feeds preventive controls, recurring-issue analytics, and ISO/IEC 20000 problem-management reporting from the same record.
Assignment rules can match on category (electrical, HVAC, plumbing, cleaning, safety), site, asset class, severity, vendor scope, or skill match against the workforce skill matrix. Round-robin and workload-balanced routing prevent the same supervisor inheriting every issue. AI smart suggestions pre-fill likely owner from historical patterns; the inspector confirms or overrides. For programs with shift coverage, routing respects the shift schedule so an issue captured at 21:00 lands on the on-shift supervisor, not the daytime team. Routing failure (no matching rule) escalates to a documented default owner so issues never sit unassigned.
Vendors get a scoped mobile profile and web portal that surfaces only the issues, sites, and assets explicitly assigned to them. They can upload photo evidence, request information, log on-site time, and propose closure with required evidence reviewed by a named internal approver before the issue actually closes. Vendors cannot see other contractors' work, other sites' data, or any customer information unless those scopes are explicitly granted. Vendor scorecards (closure time, re-open rate, fix-quality score) are visible to both the operations team and the vendor themselves, which is what mature programs find drives behaviour faster than escalation alone. RBAC is enforced server-side so a tampered request cannot escalate visibility.
Field inspectors, contractors, and customer-facing teams raise issues directly from the Android or iOS app. The capture flow is photo-first: the inspector takes a photo, optionally annotates it on-screen, and dictates the description (Voice AI transcribes in English, Hindi, Marathi, Spanish, Arabic). GPS coordinates, inspector identity, and asset confirmation (QR or manual) attach automatically. AI smart suggestions pre-fill category and severity for one-tap confirmation. The offline-first design means capture works in basements, plant rooms, and remote sites with no signal; sync happens in the background when coverage returns.
Issue Tracking & Resolution Management on Inspectly360 connects directly to the inspection apps, checklist templates, forms, industries, and adjacent solutions linked below.
See Inspectly360 in action with a live demo tailored to your needs. No credit card required.